FixMatch - A Simple yet Effective approach to Semi Supervised Learning
Deep Neural Networks can deliver impressive performance for a variety of computer vision tasks. The key to such impressive performance is in allowing the model to ingest a very large amount of labelled data during the training stage; a process known as Supervised Learning. This learning technique, whilst unbeatable in terms of model performance, has one significant drawback; the cost of data collection. In order to achieve near human level performance in some domains tens of thousands of images may be required, each of which will need to be hand labelled which is a significant human labour cost. Equally there are many domains in which laballed data is scarce or can only be done by a highly trained expert such as in medical imaging. For many businesses, the high cost and/or scarcity of labelled data may prove to be a barrier against the adoption of AI in their business.
What is Semi-Supervised Learning?
Thankfully, there is an alternative method of learning known as Semi-Supervised Learning (SSL) which offers a solution. The premise behind SSL is that learning can be achieved with a small amount of labelled data and a much larger amount of unlabelled data. The field is not new, with approaches to SSL dating back as far as the 1960s, however there has been recent traction in an algorithm called FixMatch ( published in 2020’s NuerIPS conference ) which offers both simplicity and state of the art performance accross a number of SSL benchmarks which may be a valuable tool towards unlocking the barrier of access to labelled data for many domains. In this post we will dig deeper into the algorithm to understand how it works.
Let’s consider a cat vs dog classification task. Suppose we have thousands of images of cats and dogs but only a small proportion of these images have been labelled.

Under the normal ‘supervised’ learning method we would only be able to make use of the labelled examples. For this type of learning we would feed a single example into the model, which would then produce a confidence for each possible label. We would then adjust the model according to a loss function which is a measure of how well or how badly the model performed against the true label.

In general, the more labelled data you have, the more accurately the model will be able to predict the correct class for unseen examples. Thankfully researchers have devised methods to mitigate the effects of lack of data, namely by transforming the original input data in order to generate additional training examples. For example we can apply transformations such as flipping, rotating or cropping to the original input and feed it to the model as if a brand new example.

Consistency Regularization
What if we fed the model 2 different augmented images from the same source image? We would expect it to predict the same class, right?
This is the idea behind consistency regularization, a method commonly used in SSL training. The method ensures that the classifier output remains unaffected for unlabelled examples even if is strongly augmented.
Pseudo Labeling
Another popular SSL method that has been shown to improve model generalization is pseudo-labeling. The idea behind pseudo-labeling is to use model predictions for unlabelled images as artificial labels, and subsequently to use those artificial labels to train the same model against. It may seem counter-intuitive that training a model with it’s own predictions but it has been shown to be effective especially when only confident predictions are used as psuedo labels.
How does FixMatch work?
The FixMatch algorithm combines these 2 popular SSL methods ( pseudo-labelling and consistency regularization) into a single pipeline.
- As shown in the diagram below we first apply a weak augmentation such as random crop, flip or translation to the unlabelled input example and use this to generate a psuedo-label based on the models predicted output. Note that we discard examples that the model is not confident about.
- Next we apply a strong augmentation such as Cutout, RandAugment or CTAugment to the same input image and feed the result into the model. Then we can obtain an Unsupervised Loss based on the cross-entropy loss between the prediction of our strongly augmented image and the pseudo-label.
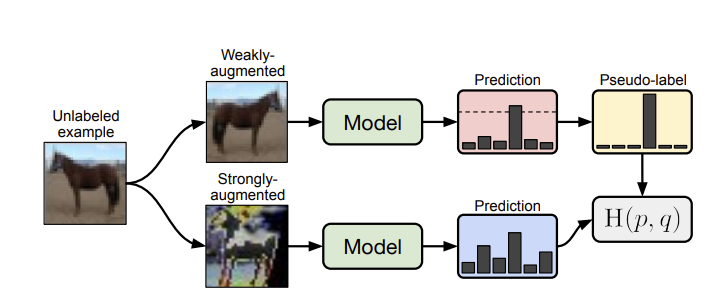
Of course, we also perform supervised learning on the labelled examples which gives us an addditional Supervised Loss. We combine these losses with a scalar hyperparameter that determines the relative contribution of the unsupervised loss in relation to the supervised loss.
Results
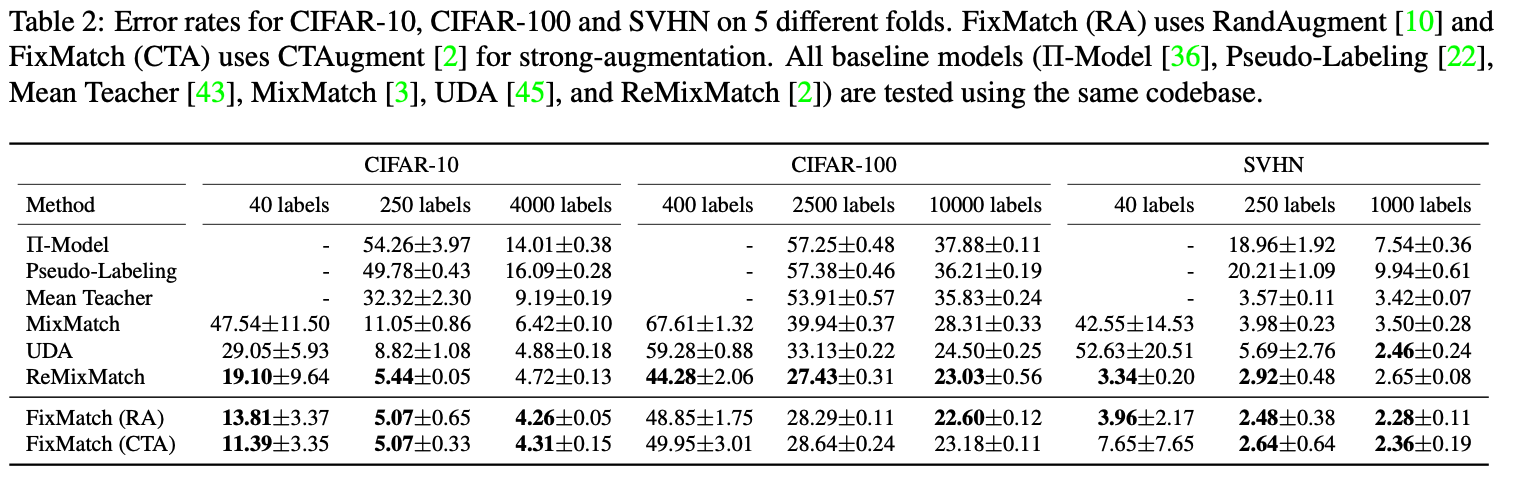
If we look at the results shown in the paper we can see that FixMatch outperforms existing SOTA methods on CIFAR-10 and SVHN datasets despite being simpler in comparison to many of the other methods. The number of labels in the table indicates the number of labeled examples that we’re used with the remainder of the dataset being treated as unlabelled. Given that CIFAR-10 contains 10 classes that means with just 4 labelled examples per class FixMatch was able to achieve an averge error rate of just 11.39%.
The authors also evaluated the model on ImageNet to verify it’s efficacy on larger, more complex datasets. They sample 10% of the data to treat as labeled examples and the remaining 90% is considered as unlabelled. They managed to achieve a top-1 error rate of 28.54 +/- 0.52 and a top-5 error rate of 10.87 +/- 0.28 which is better than UDA and impressive considering the simplicity of the approach.
Conclusion
To sum up, owing to it’s relative simplicity and state of the art performance on a number of SSL image classification benchmarks, FixMatch presents promising tool to help break the barrier towards the adoption of machine learning that is presented by the lack of labelled data.
The paper is available here
The code is available on github here